上一章我们认识了寄存器和 x64dbg 窗口。但寄存器只有 8 个,存不了多少东西。程序的大部分数据存在内存里,通过地址来访问。这章先搞懂汇编怎么表示和访问内存,再生成一个练习用的空白程序。
内存怎么表示
汇编里访问内存用方括号 [],类似 C 的指针解引用 *ptr:
mov eax, [ebp-4] ; 从内存地址 (ebp-4) 读 4 字节到 eax
mov [ebp-8], eax ; 把 eax 的值写到内存地址 (ebp-8)x64dbg 里显示更详细,会带大小前缀:
mov eax, dword ptr [ebp-4]
mov dword ptr [ebp-8], eax大小前缀
dword ptr 意思是”这次读/写 4 个字节”。CPU 需要知道操作多大的数据。怎么知道的?两种方式:
方式一:从寄存器推断。 如果一个操作数是寄存器,CPU 根据寄存器大小决定:
mov eax, [ebp-4] ; EAX 是 32 位,所以读 4 字节
mov ax, [ebp-4] ; AX 是 16 位,所以读 2 字节
mov al, [ebp-4] ; AL 是 8 位,所以读 1 字节方式二:显式指定。 如果没有寄存器可以推断(比如两个操作数都是常数或内存),必须写明:
mov dword ptr [ebp-4], 0 ; 明确写 4 字节的 0
mov word ptr [ebp-4], 0 ; 明确写 2 字节的 0
mov byte ptr [ebp-4], 0 ; 明确写 1 字节的 0大小前缀对照表:
| 前缀 | 大小 | 名称 | 对应 C 类型 | 汇编声明 |
|---|---|---|---|---|
byte ptr | 1 字节 | 字节 | char, bool | db |
word ptr | 2 字节 | 字 | short | dw |
dword ptr | 4 字节 | 双字 | int, unsigned int, float | dd |
qword ptr | 8 字节 | 四字 | long long, double | dq |
最右边一列是汇编语言里的数据声明伪指令:db(define byte)、dw(define word)、dd(define dword)、dq(define qword)。你在 IDA 或 x64dbg 的数据窗口里看到 dd 12345678h,就是在说”这里定义了一个 4 字节数据,值是 0x12345678”。
dword ptr 最常见,因为 int 是 4 字节。偶尔看到 byte ptr(char)和 word ptr(short)。
地址是怎么算出来的
方括号里的表达式叫做有效地址(Effective Address),计算公式是:
有效地址 = 基址 + 索引 × 比例 + 偏移x64dbg 支持几种格式:
| 格式 | 示例 | 场景 |
|---|---|---|
[固定地址] | mov eax, dword ptr [0040A000] | 全局变量 |
[寄存器] | mov eax, dword ptr [ecx] | 解引用指针 |
[寄存器 + 偏移] | mov eax, dword ptr [ebp-4] | 局部变量 |
[寄存器 + 寄存器*比例] | mov eax, dword ptr [ecx + edx*4] | 指针访问数组 |
[寄存器 + 寄存器*比例 + 偏移] | mov eax, dword ptr [ebp+eax*4-10] | 栈上局部数组 |
后两种通常用于数组和结构体访问,先混个眼熟,后面遇到再回来查。
不管哪种格式,有效地址的计算方式都是一样的:把各部分加起来。下面用公式标准格式演示,实际 Debug 模式下你会看到 [ebp + eax*4 - 偏移] 的形式(原因见后面的 NOTE)。
假设 EBP = 0x012FF310:
mov eax, dword ptr [ebp-4]有效地址 = 0x012FF310 - 4 = 0x012FF30C。CPU 去 0x012FF30C 这个地址读 4 字节,放进 EAX。
mov eax, dword ptr [ecx + edx*4]假设 ECX = 0x0040A000,EDX = 3。有效地址 = 0x0040A000 + 3*4 = 0x0040A00C。这就是数组第 3 个元素(每个元素 4 字节)的地址。
在 x64dbg 里看到内存寻址时,怎么判断它在访问什么?看基址寄存器:
[ebp - 8]、[ebp + 10]→ 几乎一定是局部变量,EBP 是当前函数的栈帧基址[eax]、[ecx]→ 寄存器里存的是一个指针,正在解引用[ecx + edx*4]→ 数组访问,ecx是首地址,edx是下标,*4说明每个元素 4 字节(int)[ebp + eax*4 - 20]→ 栈上的局部数组,ebp-20是首地址,eax是下标
看到 *4 说明每个元素 4 字节,多半是 int 数组。
为什么 x64dbg 里看不到 [ecx + edx*4]?
[ecx + edx*4]?上面的例子用了 [ecx + edx*4] 这种干净格式,但你在 x64dbg 里实际看到的数组访问几乎都是 [ebp + eax*4 - 10] 这种带偏移的形式。
原因很简单:Debug 模式下,局部变量都分配在栈上,每个变量有固定的位置。比如 int iarr[3] 的首地址是 ebp-10,那 iarr[x] 的地址就是:
首地址 + 下标 × 4 = (ebp - 10) + x*4这就是 [ebp + eax*4 - 10],公式还是同一个,只不过基址和偏移都是栈上的具体位置。
想看到纯粹的 [ecx + edx*4],有两种方法:
- 用指针访问数组:
int *p = iarr; p[x];,编译器必须先把首地址放进寄存器,就会生成干净的格式 - 切换到 Release 模式:编译器会把变量放进寄存器而不是栈上,偏移自然消失
不管格式长什么样,读懂的方法都一样:ebp-10 是数组首地址,eax 是下标,*4 是每个元素的字节数。
搞懂了地址怎么算,还有一个问题:数据在内存里是怎么排的? 同一个地址,读出来的字节顺序是大端还是小端,决定了你看到的数值。x86 用的是小端序。
大小端
x86 是小端序(Little-Endian),低字节存在低地址。
比如 EAX = 0x12345678,写到 [ebp-4] 时,内存里是这样的:
地址 字节
[ebp-4] 78 <- 最低字节在最低地址
[ebp-3] 56
[ebp-2] 34
[ebp-1] 12 <- 最高字节在最高地址所以在 x64dbg 的内存窗口里,你看到 78 56 34 12,要反着读,实际值是 0x12345678。
为什么 x86 用小端? 你在纸上算加法,一定从个位开始,因为要处理进位。CPU 做加法也是一样的,必须先拿到低位,算出进位,再算高位。
小端序恰好把低位放在最低地址。CPU 从内存读数据时,最先读到的就是低位,直接送进加法器就能算,一路往高地址推进就行。如果用大端序,低位存在更高的地址,CPU 得先跳过去取低位,算完再退回来处理高位,多了一趟折腾。
8 位总线时代的历史真相
这个”先低位再高位”的优势在 8 位总线时代最明显。70 年代的 CPU(如 8080)一次只能从内存读 1 个字节,但寄存器是 16 位的。算 0x1122 + 0x3344 时:
- 小端序:内存里先存低位(
22、44),CPU 从低地址一路往下读,边读边算,指针只往一个方向走。 - 大端序:内存里先存高位(
11、33),CPU 必须先跳到后面取低位,算完进位再退回来取高位,地址总线来回折腾。
小端序用最少的晶体管、最简单的电路就能完成 16 位加法。现在 CPU 总线都是 64 位了,一次能吞好几个字节进缓存,大端小端的硬件差距已经被抹平,但 x86 的选择从 70 年代沿用至今。
小端序还有一个附带好处:同一地址读取不同宽度时,起始地址不变。比如地址 0x100 存了 0x12345678:
- 读 byte:
[0x100]=0x78 - 读 word:
[0x100]=0x5678 - 读 dword:
[0x100]=0x12345678
都是 0x100 起,不需要为不同宽度换起始地址。
大小端在不同窗口的表现
同样的数据 0x12345678,在不同窗口里看起来不一样:
| 窗口 | 显示样子 | 说明 |
|---|---|---|
| CPU 窗口 | mov dword ptr [ebp-4], 12345678 | 指令里直接写正常数值,不需要反着读 |
| 寄存器窗口 | EAX : 12345678 | 也是正常显示 |
| 内存窗口 | 78 56 34 12 | 按字节顺序显示,需要反着读 |
| 堆栈窗口 | 78 56 34 12 | 同内存窗口,按字节显示,需要反着读 |
规律:CPU 窗口和寄存器窗口已经帮你把小端序转换好了,直接看。只有内存窗口和堆栈窗口是原始字节流,需要你自己反着读。
这其实就是”显示方式”的区别:内存窗口是”这块内存里到底存了什么字节”,是原始的、底层的;CPU 窗口和寄存器窗口是”这些字节代表什么数值”,是经过解读的。
生成一个练习用的空白程序
后面的章节会经常让你在 x64dbg 里手写汇编指令来实验。你需要一个代码段全是 NOP 的 exe,相当于一块空白画布,想写什么指令都可以。
用 C 写一个全是 __nop() 的函数?不太干净,编译器会偷偷加各种初始化代码。最纯粹的方法是用 MASM(Microsoft Macro Assembler),直接写汇编源码,编译出来的 exe 代码段就是你写的那些指令,不多不少。
步骤
-
打开 VS,创建一个 C++ 空项目(Empty Project)
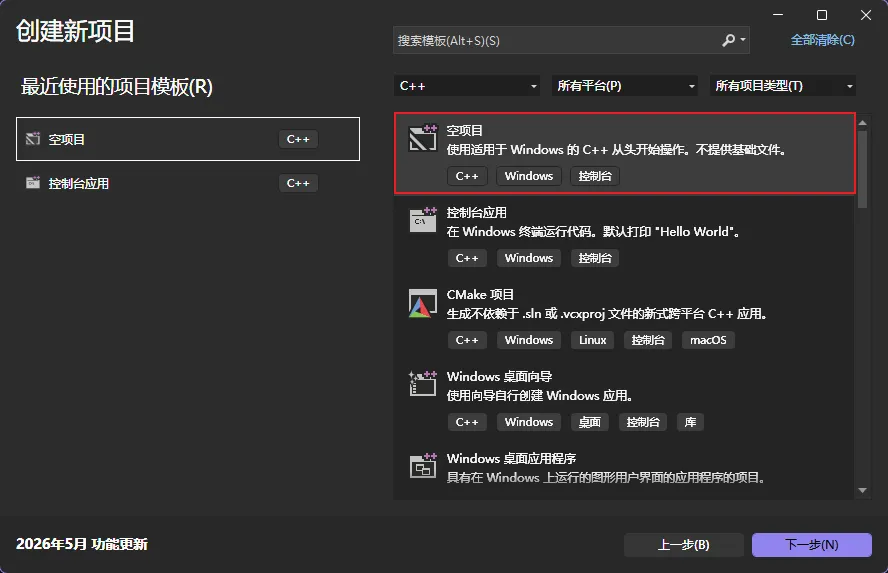
-
在右侧解决方案资源管理器中,右键项目名称 -> 生成依赖项(Build Dependencies) -> 生成自定义(Build Customizations…)
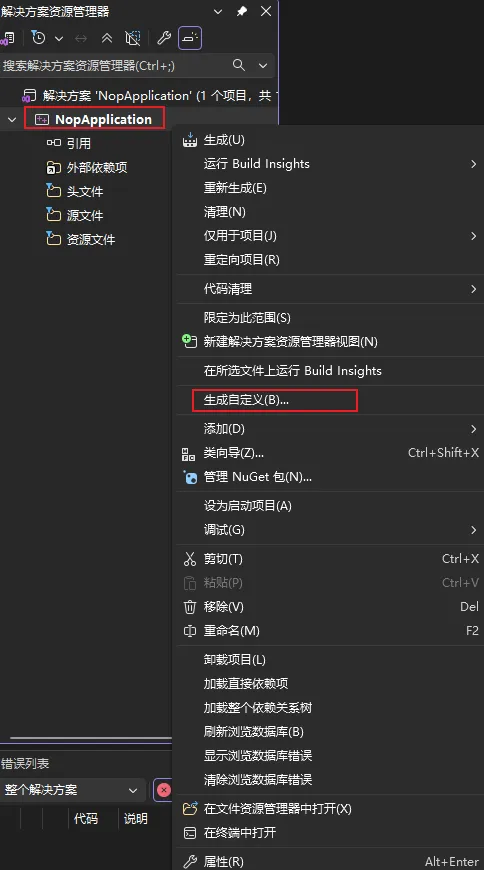
在弹出的窗口中勾选 masm -> 确定
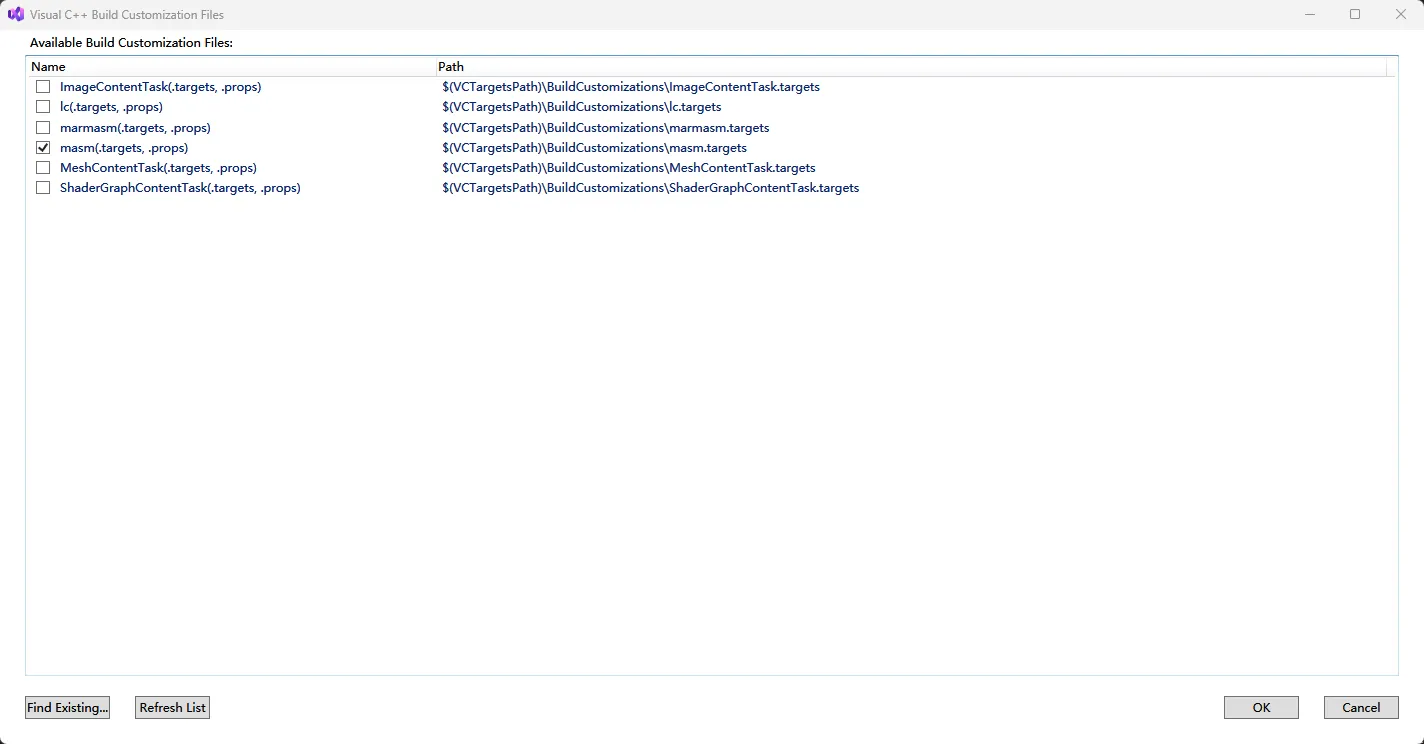
-
在右侧解决方案资源管理器中,右键”源文件”文件夹 -> 添加 -> 新建项 -> 创建一个名为
main.asm的文件(后缀必须是.asm)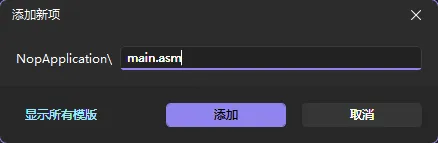
-
把项目顶部的配置改成 Release | x86(我们要生成 32 位程序,且 Release 模式不会有额外的调试代码)
-
右键
main.asm-> 属性,把项类型(Item Type) 改为 Microsoft Macro Assembler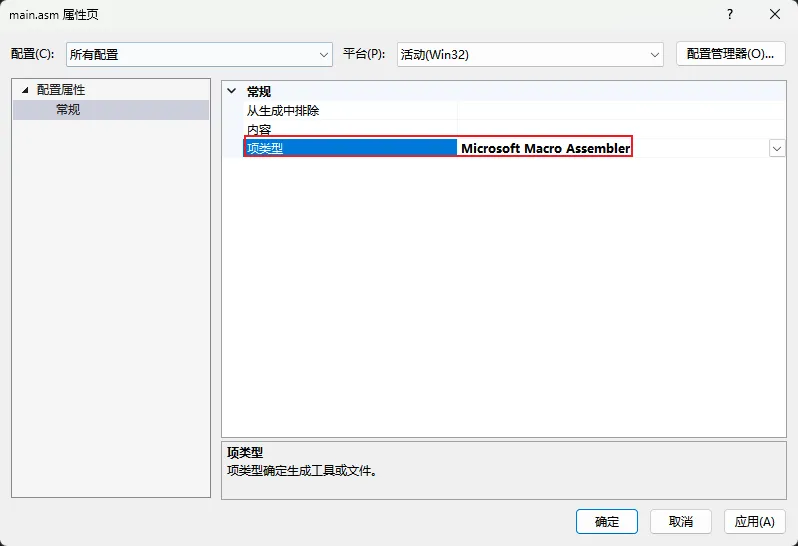
-
把
main.asm的内容替换成:
.386 ; 声明使用 80386 处理器指令集
.model flat, stdcall ; 32位 Windows 必须的平坦内存模型
.code ; 代码段开始
_main PROC ; 32位下,内部函数名加个下划线 _main
; 循环生成 4096 个 NOP
REPT 4096
nop
ENDM
ret
_main ENDP
END ; 结束-
设置入口点:右键项目 -> 属性 -> 链接器(Linker) -> 高级(Advanced) -> 把入口点(Entry Point) 改为
_main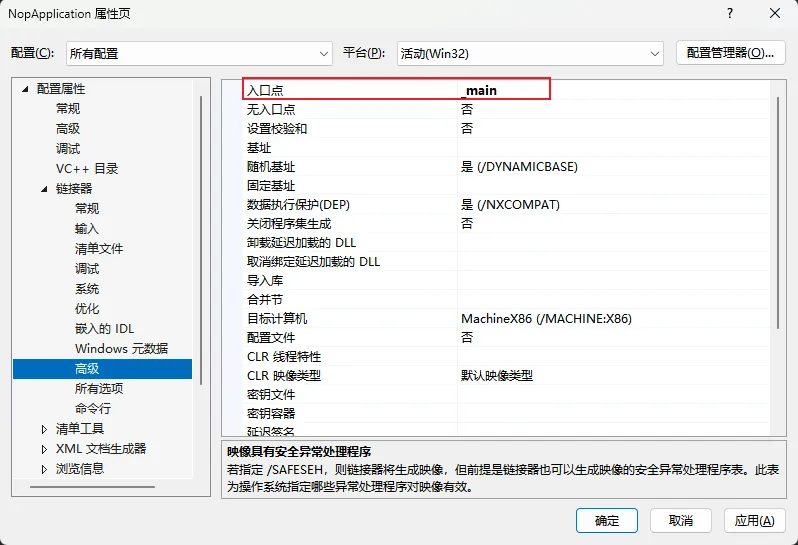
-
关闭安全异常处理:同在链接器 -> 高级页面,把映像具有安全异常处理程序(Image Has Safe Exception Handlers) 改为 否(/SAFESEH:NO)
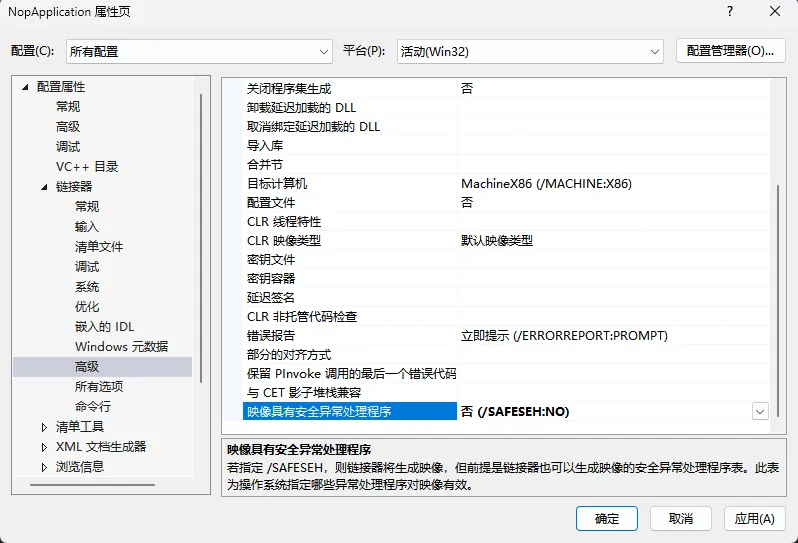
-
按 Ctrl+B 编译
-
用 x32dbg 打开生成的 exe,按 Alt+F9 跳到用户代码,你会看到一大片
nop,就是你的空白画布
和第一章一样,建议关闭 ASLR 和增量链接(项目属性 -> 链接器),这样每次编译后地址固定。是否启用 ASLR 取决于链接器的 /DYNAMICBASE 设置;如果在 MASM 项目里找不到这些选项,记得额外确认生成的 exe 是否真的关闭了地址随机化。
怎么用这块画布
在 x64dbg 里怎么找到那片 NOP 区域?程序加载后会停在系统断点,按 Alt+F9(执行到用户代码)就能跳到你的 NOP 区域。按 空格键,输入你想实验的指令(比如 mov eax, 0x12345678),回车确认。光标自动移到下一行,你可以继续输入下一条。输入完毕后在第一条按 F2 设断点,F9 运行到这里,然后 F8 单步执行,观察寄存器和标志位的变化。
后面每章的 x64dbg 实操都可以用这个程序来练习。写错了也不用怕,重新把 exe 拖进 x32dbg 就恢复原样了。
你手写的指令不能超出 NOP 区域的边界。4096 个 NOP = 4096 字节的空间,对练习来说绰绰有余。如果输入的指令太多超出了,可能会覆盖到后面的 ret,程序退出时就会出问题。遇到这种情况重新拖进去就行。
练习
-
假设 EBP =
0x012FF310,mov eax, dword ptr [ebp-8]读取的内存地址是多少?参考答案0x012FF308(即0x012FF310 - 8)。 -
内存地址
0x012FF308处存着EF BE AD DE(按字节顺序)。作为 32 位整数读取,值是多少?参考答案0xDEADBEEF。内存窗口显示的是小端序(低字节在低地址),要反着读:DE AD BE EF->0xDEADBEEF。 -
ECX =
0x0040A000,EDX =5,mov eax, dword ptr [ecx + edx*4]读取的地址是多少?参考答案0x0040A014(即0x0040A000 + 5*4)。这就是数组array[5](每个元素 4 字节)的地址。 -
打开你生成的
nop.exe,在第一个 NOP 处按空格,输入mov dword ptr [ebp-4], 0x12345678。这条指令机器码占多少字节?(看机器码列)参考答案取决于具体编码,通常是 7 字节左右(
C7 45 FC 78 56 34 12)。你可以观察:机器码最后的78 56 34 12就是要写入的值0x12345678的小端序表示。