为什么要学汇编
上一章你破解了自己的第一个程序,在 x64dbg 里看到了一堆汇编指令。我们通过搜索字符串找到关键跳转,但如果每次都靠这种办法碰运气,效率太低了。
CPU 真正执行的是机器码,也就是一串串二进制数字。 汇编是机器码的人类可读形式:每条机器指令对应一行汇编文本。你用 C 写的代码,编译器先翻译成机器码,调试器再把它反汇编成汇编显示给你。所以看懂汇编,就等于看懂了程序在 CPU 层面的每一个动作。这比看 C 源码更底层,但信息已经足够你理解程序的逻辑。
好消息是:逆向用到的汇编指令不多,常用的就十几条。接下来的几章把最重要的过一遍,后面章节会反复练习。
前置知识:十六进制、位和字节
在看汇编之前,你必须先搞懂三个基础概念—因为后面每一页都在用它们。
位(bit)
位是计算机最小的数据单位,只有两个值:0 或 1。 计算机内部所有数据都用位表示。
一位就是一个开关:开(1)或关(0)。你平时见到的所有数据—数字、文字、图片、程序—底层都是一堆 0 和 1。
单独一个位能表示的信息很少(只有两种),所以位通常组合起来用。
字节(byte)
8 个位排在一起就是一个字节。 这是计算机处理数据的基本单位。
一个字节 = 8 位,能表示 2^8 = 256 种不同的值(0 ~ 255,或 0x00 ~ 0xFF)。
为什么是 8 个一组?因为早期计算机用 8 位刚好够表示一个英文字母(ASCII 编码)。这个传统延续至今—内存的最小可寻址单位就是字节,不是位。
你后面会反复看到的几个术语:
| 名称 | 英文 | 位数 | 字节数 |
|---|---|---|---|
| 字节 | byte | 8 | 1 |
| 字 | word | 16 | 2 |
| 双字 | dword | 32 | 4 |
32 位程序里,一个 int 就是 4 字节(双字),一个地址也是 4 字节。暂时不会碰到 64 位的四字(qword)。
十六进制
你在 x64dbg 里看到的数值几乎全是十六进制(hexadecimal)—用 0 ~ 9 和 A ~ F 这 16 个符号来表示数值。
为什么不用十进制?因为十六进制和二进制之间的转换非常整齐:每 4 个二进制位 = 1 个十六进制位。 这让十六进制成为”人类可读的二进制”。
二进制 十六进制 十进制
0000 0 0
0001 1 1
0010 2 2
...
1001 9 9
1010 A 10
1011 B 11
1100 C 12
1101 D 13
1110 E 14
1111 F 15所以一个字节(8 位)恰好用两位十六进制表示:
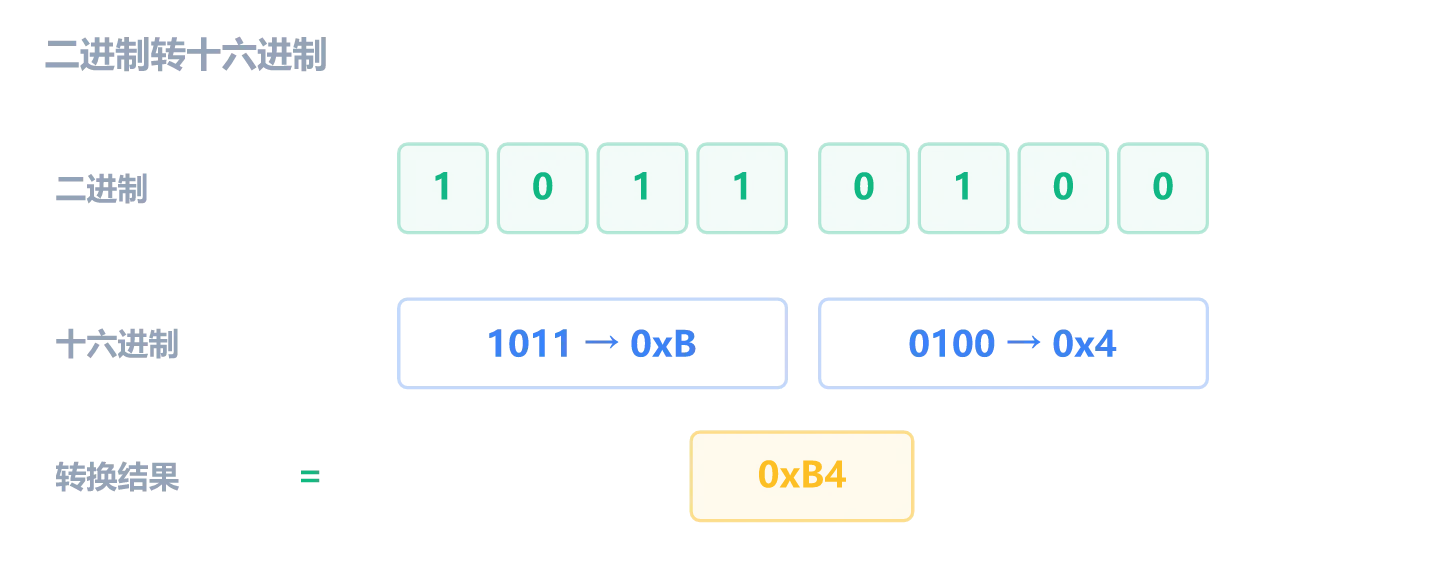
在 x64dbg 和 C 代码里,十六进制通常用 0x 前缀,比如 0xFF、0x00401000。有时也用 h 后缀,比如 B4h。没有前缀也没有后缀的数字默认是十进制。
正数和负数:一个字节的故事
到目前为止,我们说的都是”无符号”整数,即一个字节存 0 ~ 255。但程序里经常要用负数。那一个字节怎么既存正数又存负数呢?
答案是:把 256 个状态劈成两半。 最高位当符号位:0 开头的是正数,1 开头的是负数。
用数轴看最直观:
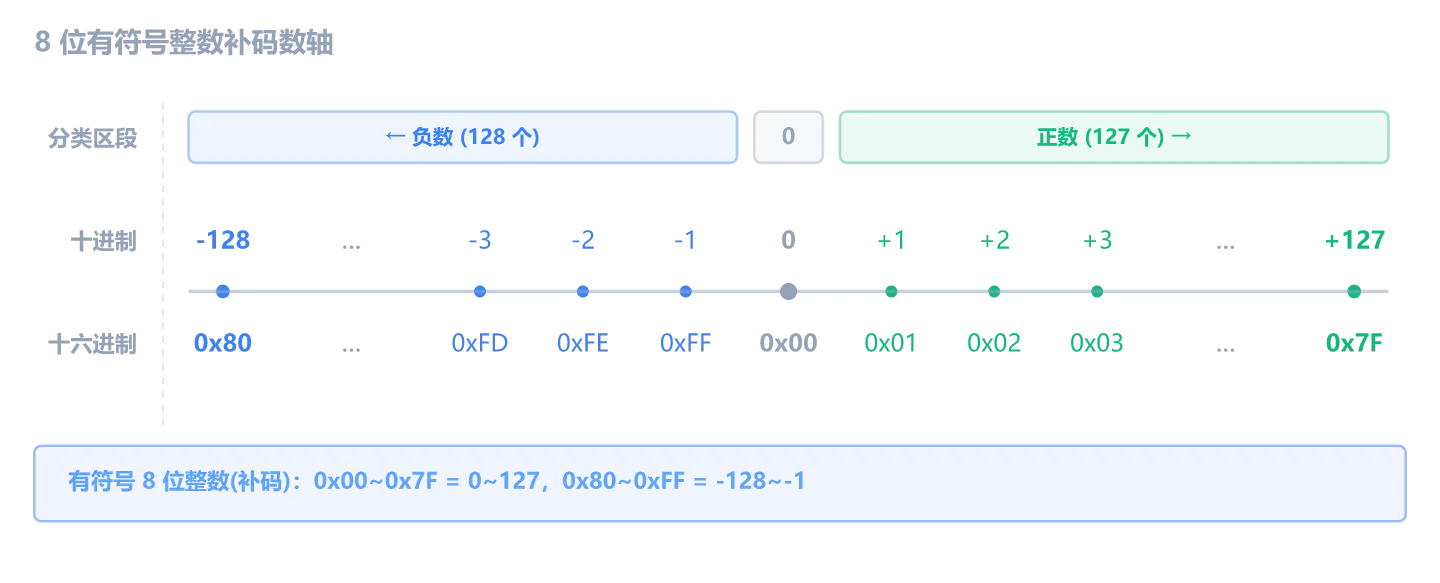
这张数轴分两半:左半(0x80 ~ 0xFF)是负数,右半(0x00 ~ 0x7F)是正数。记住这个分界线,后面看 x64dbg 里的十六进制值时就能快速判断正负。
几个关键数字:
- 正数从
0x01到0x7F(0 开头,最高位是 0)。最大正数 =0x7F= 127 - 负数从
0x80到0xFF(1 开头,最高位是 1)。最小负数 =0x80= -128 - 0 在正数那边(
0x00,符号位为 0)。所以正数有 128 个(0 ~ +127),负数有 128 个(-128 ~ -1),总共还是 256 = 2^8
负数怎么跟十六进制对应? 计算机用 补码(Two’s Complement) 编码,规则是:取反加一。
举个例子,-2 在一个字节里长什么样?
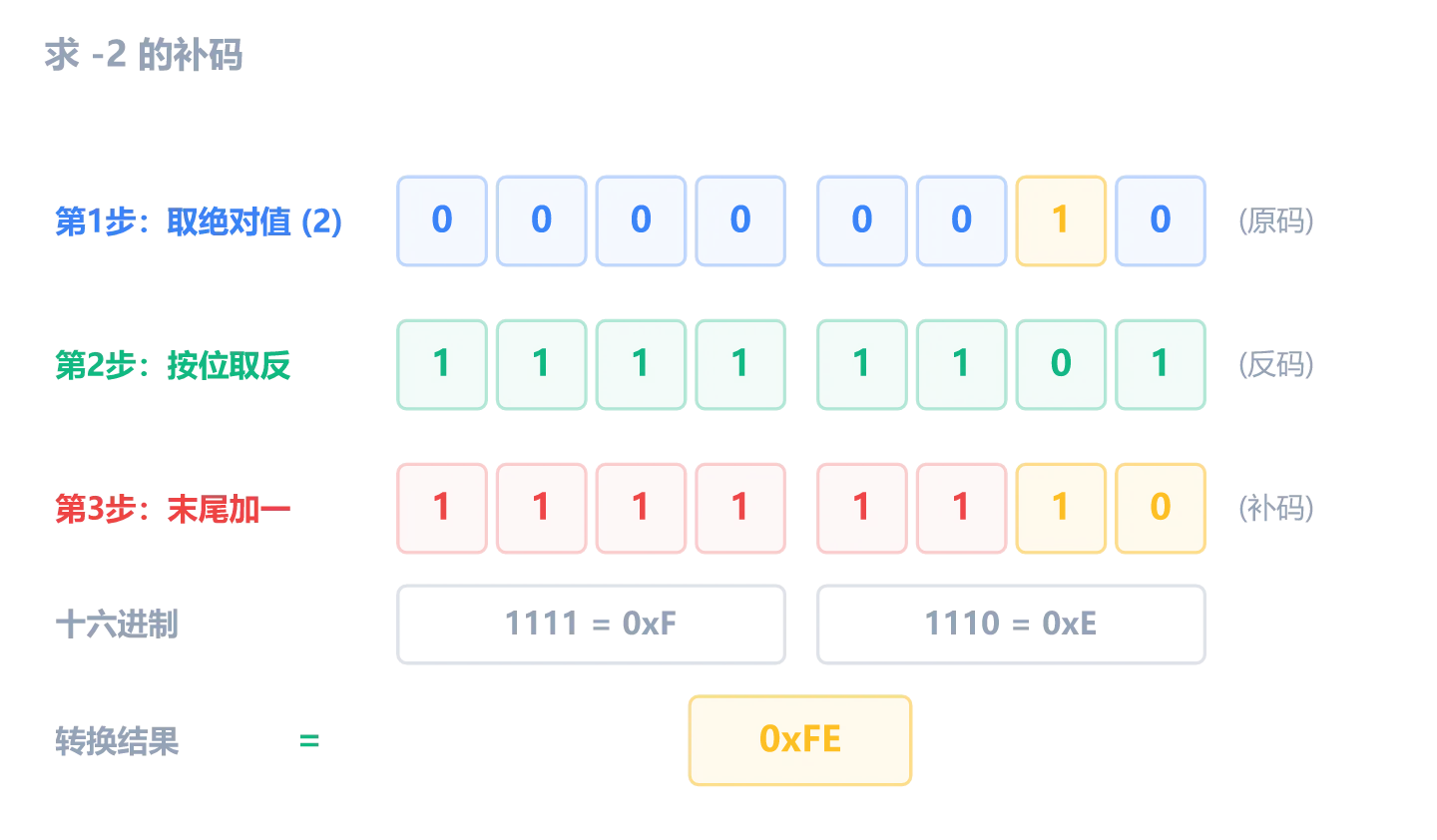
反过来,看到 0xFE 怎么知道是 -2?同样的操作再做一遍:
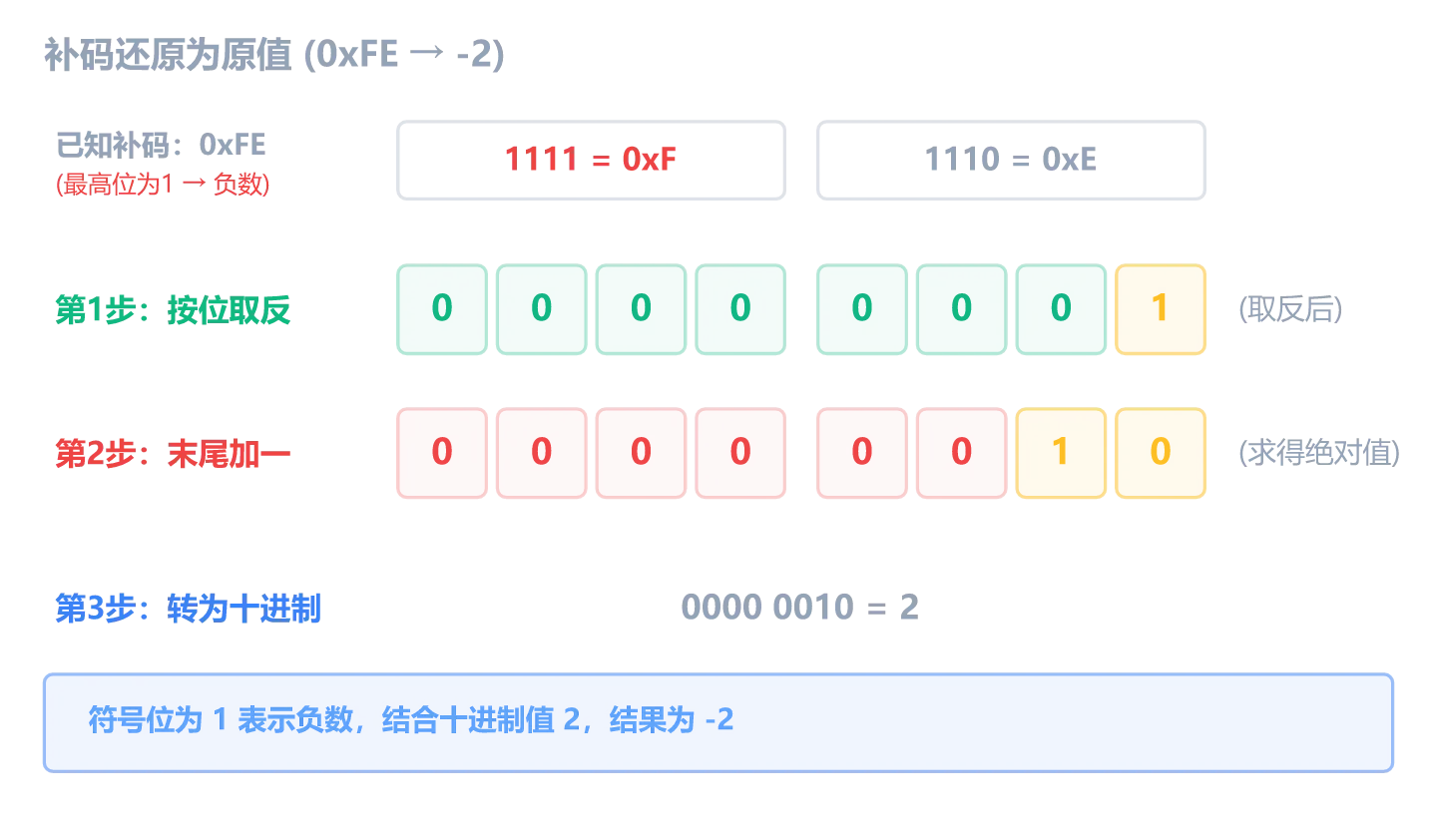
自己验证一下:0xFF 取反加一得到多少?
- 取反
0000 0000 - 加一
0000 0001= 1
所以 0xFF = -1。
为什么”取反加一”就行? 任何数加上自己的取反结果,每一位都是 0+1=1,所以 x + ~x = 0xFF...FF(全 1)。全 1 再加 1 就溢出变成 0x00...00。也就是说:
x + (~x + 1) = 0
加起来等于 0 的那个数就是 -x。所以 ~x + 1(取反加一)就是 -x 的编码。
快速判断负数:十六进制最高位 ≥ 8(即 8、9、A、B、C、D、E、F),说明二进制最高位是 1,作为有符号数就是负数。比如 0xFE(F ≥ 8)是负数,0x7F(7 < 8)是正数。
8 位、16 位、32 位的范围
上面用 8 位讲的原理,对 16 位和 32 位完全一样—只是位数多了,范围更大:
| 位数 | 最大无符号值 | 无符号范围 | 最大正数 | 最小负数 | 有符号范围 |
|---|---|---|---|---|---|
| 8 | 0xFF | 0 ~ 255 | 0x7F | 0x80 | -128 ~ +127 |
| 16 | 0xFFFF | 0 ~ 65,535 | 0x7FFF | 0x8000 | -32,768 ~ +32,767 |
| 32 | 0xFFFFFFFF | 0 ~ 4,294,967,295 | 0x7FFFFFFF | 0x80000000 | -2,147,483,648 ~ +2,147,483,647 |
32 位那个 0xFFFFFFFF ≈ 43 亿,看起来很大,但其实就是四个字节全填 F。在 x64dbg 里你看到的地址和 int 值都是 32 位的,所以这个范围你每天都会碰到。
规律一眼能看出来:
- 最大正数永远是
0x7F...F(最高位 0,其余全 1) - 最小负数永远是
0x80...0(最高位 1,其余全 0) - -1 永远是全 F:
0xFF(8 位)、0xFFFF(16 位)、0xFFFFFFFF(32 位)
核心结论:同一个十六进制值,可以有”无符号”和”有符号”两种解读。0xFFFFFFFF 作为无符号是最大值,作为有符号就是 -1。程序把它当哪种用,取决于上下文。后面学到 EFLAGS 标志位时,你会看到 CPU 怎么同时算出两组标志位(CF 和 OF),分别服务于这两种解读。
小数怎么办?
到目前为止我们只讲了整数。程序里当然也有小数—C 语言里的 float 和 double。
但小数在计算机里的编码方式(叫 IEEE 754 浮点数)跟整数完全不同:它把 32 位拆成三段—符号位、指数、尾数—用类似科学计数法的方式存。比如 0.1 在内存里不是你想的那样存的,0.1 + 0.2 在计算机里也不精确等于 0.3。
逆向实战中 95% 遇到的都是整数运算。CrackMe、注册码、游戏辅助,几乎全是整数。浮点主要出现在图形计算、物理引擎等场景。我们先不展开浮点,等后面碰到浮点指令(movss、addss 之类的 SSE 指令)时再专门讲。
从 C 源码到机器码
搞懂了基础概念,现在看看汇编在整体流程中的位置。
你写 C 代码 -> 编译器编译 -> 生成 exe -> 你用 x64dbg 打开 exe -> 看到汇编。这个流程是这样的:
flowchart LR
A["C 源代码 (.c)"] --> B["编译器\n翻译成汇编+机器码"]
B --> C["链接器\n合并目标文件"]
C --> D["exe 文件 (二进制)"]
D --> E["x64dbg 反汇编\n机器码 -> 汇编"]几个关键概念:
- 源代码 — 你写的 C 代码,人类可读
- 编译 — 编译器把 C 翻译成汇编,再把汇编翻译成机器码(二进制)。这一步是不可逆的:编译完成后,大部分源码级信息都会丢失,比如局部变量名、注释和原始控制结构;但导入函数名、导出符号、字符串甚至调试信息有时仍会保留
- 链接 — 把多个目标文件和库合并成一个 exe
- 反汇编 — 逆向工程的第一步。x64dbg 把 exe 里的机器码翻译回汇编,给我们看。但原始的 C 代码是拿不回来的
反编译工具(如 IDA、Ghidra)可以尝试从汇编还原出接近 C 的代码,但只是”尽力而为”—变量名没了、注释没了、有些代码结构会变。不要指望反编译结果和源码一模一样。
所以汇编是逆向工程师能看到的”最接近源代码”的东西。 看懂汇编 = 看懂程序在做什么。
回顾第 1 章:你改的那个字节到底改了什么
还记得第一章吗?你把 jne 改成 je(方法二),效果就反过来了—输错密码反而显示 Correct,输对密码反而显示 Wrong。
现在你已经有了理解它的知识:
jne的意思是”Jump if Not Equal”—如果 ZF=0 就跳转- 程序比较你输入的序列号和正确的序列号,相等时 ZF=1,不相等时 ZF=0
- 原本
jne检查 ZF=0(不相等)-> 跳到”错误”分支,ZF=1(相等)-> 不跳,走”正确”分支 - 你改成
je后,跳转条件反过来了:ZF=1(相等)-> 跳到”错误”分支,ZF=0(不相等)-> 不跳,走”正确”分支 - 所以输错密码时 ZF=0,
je不跳,走了 Correct 分支
这一个小字节的改动,本质上是把条件跳转的判断逻辑取反了。
下一章我们会打开 x64dbg,亲眼看到这些寄存器、标志位和内存地址。
练习
-
手动算补码:用 8 位表示
-5,写出二进制和十六进制。再用”取反加一”验证回去。参考答案-5 的编码: 取绝对值 5 = 0000 0101 取反 = 1111 1010 加一 = 1111 1011 = 0xFB 验证回去: 0xFB = 1111 1011 取反 = 0000 0100 加一 = 0000 0101 = 5 ✓ -
十六进制转二进制:
0x3C和0xA5各等于什么二进制?(提示:每位十六进制 = 4 位二进制,逐位展开就行)参考答案0x3C=0011 1100,0xA5=1010 0101 -
二进制转十六进制:
1100 1010和0001 1111各等于什么十六进制?参考答案1100 1010=0xCA,0001 1111=0x1F -
读十六进制:
0xFFFFFFFE作为 32 位有符号数是多少?作为无符号数是多少?参考答案有符号 =
-2(取反加一验证:~0xFFFFFFFE + 1 = 0x00000001 + 1 = 0x00000002 = 2,所以是-2),无符号 =4,294,967,294 -
判断正负:下列十六进制值作为有符号数是正数还是负数?
0x3A、0xA0、0x7FFFFFFF、0x80000001参考答案0x3A(3 < 8,正数)、0xA0(A ≥ 8,负数)、0x7FFFFFFF(7 < 8,正数)、0x80000001(8 ≥ 8,负数)